Tutorial: Data Registry Basics
Building registries
Adding datasets to a registry can be as simple as placing the data file or
directory in question inside the workspace, and track it with
dvc add. A standard Git workflow can be followed with the .dvc files that
substitute the actual data (e.g. music/songs.dvc below). This enables team
collaboration on data at the same level as with source code:
This sample dataset actually exists.
$ mkdir -p music/songs
$ cp ~/Downloads/millionsongsubset_full music/songs
$ dvc add music/songs/
$ git add music/songs.dvc music/.gitignore
$ git commit -m "Track 1.8 GB 10,000 song dataset in music/"The actual data is stored in the project's cache, and can be pushed to one or more remote storage locations so the registry can be accessed from other locations and by other people:
$ dvc remote add -d myremote s3://mybucket/dvcstore
$ dvc push💡 A good way to organize DVC repositories into data registries is to use directories to group similar data, e.g.
images/,natural-language/, etc. For example, our dataset registry has directories likeget-started/anduse-cases/, matching parts of this website.
Using registries
The main methods to consume artifacts from a data registry are
the dvc import and dvc get commands, as well as the Python API dvc.api.
But first, we may want to explore its contents.
Listing data
To explore the contents of a DVC repository in search for the right data, use
the dvc list command (similar to ls and 3rd-party tools like aws s3 ls):
$ dvc list -R https://github.com/iterative/dataset-registry
.gitignore
README.md
get-started/.gitignore
get-started/data.xml
get-started/data.xml.dvc
images/.gitignore
images/dvc-logo-outlines.png
...Both Git-tracked files and DVC-tracked data (or models, etc.) are listed.
Data downloads
dvc get is analogous to using direct download tools like wget (HTTP),
aws s3 cp (S3), etc. To get a dataset from a DVC repo, we can run something
like this:
$ dvc get https://github.com/example/registry music/songsThis downloads music/songs from the project's
default remote and places it in the
current working directory.
Data import workflow
dvc import uses the same syntax as dvc get:
$ dvc import https://github.com/example/registry images/facesBesides downloading the data, importing saves the information about the
dependency that the local project has on the data source (registry repo). This
is achieved by generating a special import .dvc file, which contains this
metadata.
Whenever the dataset changes in the registry, we can bring data up to date in
with dvc update:
$ dvc update faces.dvcThis downloads new and changed files, and removes deleted ones, based on the
latest commit in the source repo; And it updates the .dvc file accordingly.
Note that
dvc get,dvc import, anddvc updatehave a--revoption to download data from a specific commit of the source repository.
Using DVC data from Python code
Our Python API, included with the dvc package installed
with DVC, includes the open function to load/stream data directly from
external DVC projects:
import dvc.api
model_path = 'model.pkl'
repo_url = 'https://github.com/example/registry'
with dvc.api.open(model_path, repo_url) as f:
model = pickle.load(f)
# ... Use the model!This opens model.pkl as a file-like object. This example illustrates a simple
ML model deployment method, but it could be extended to more advanced
scenarios such as a model zoo.
See also the dvc.api.read() and dvc.api.get_url() functions.
Updating registries
Datasets evolve, and DVC is prepared to handle it. Just change the data in the
registry, and apply the updates by running dvc add again:
$ cp 1000/more/songs/* music/songs/
$ dvc add music/songs/DVC modifies the corresponding .dvc file to reflect the changes, and this is
picked up by Git:
$ git status
...
modified: music/songs.dvc
$ git commit -am "Add 1,000 more songs to music/ dataset."Iterating on this process for several datasets can give shape to a robust registry. The result is basically a repo that versions a set of metafiles. Let's see an example:
$ tree --filelimit=10
.
├── images
│ ├── .gitignore
│ ├── cats-dogs [2800 entries] # Listed in .gitignore
│ ├── faces [10000 entries] # Listed in .gitignore
│ ├── cats-dogs.dvc
│ └── faces.dvc
├── music
│ ├── .gitignore
│ ├── songs [11000 entries] # Listed in .gitignore
│ └── songs.dvc
├── text
...And let's not forget to dvc push data changes to the remote storage, so others
can obtain them!
$ dvc pushManaging registries
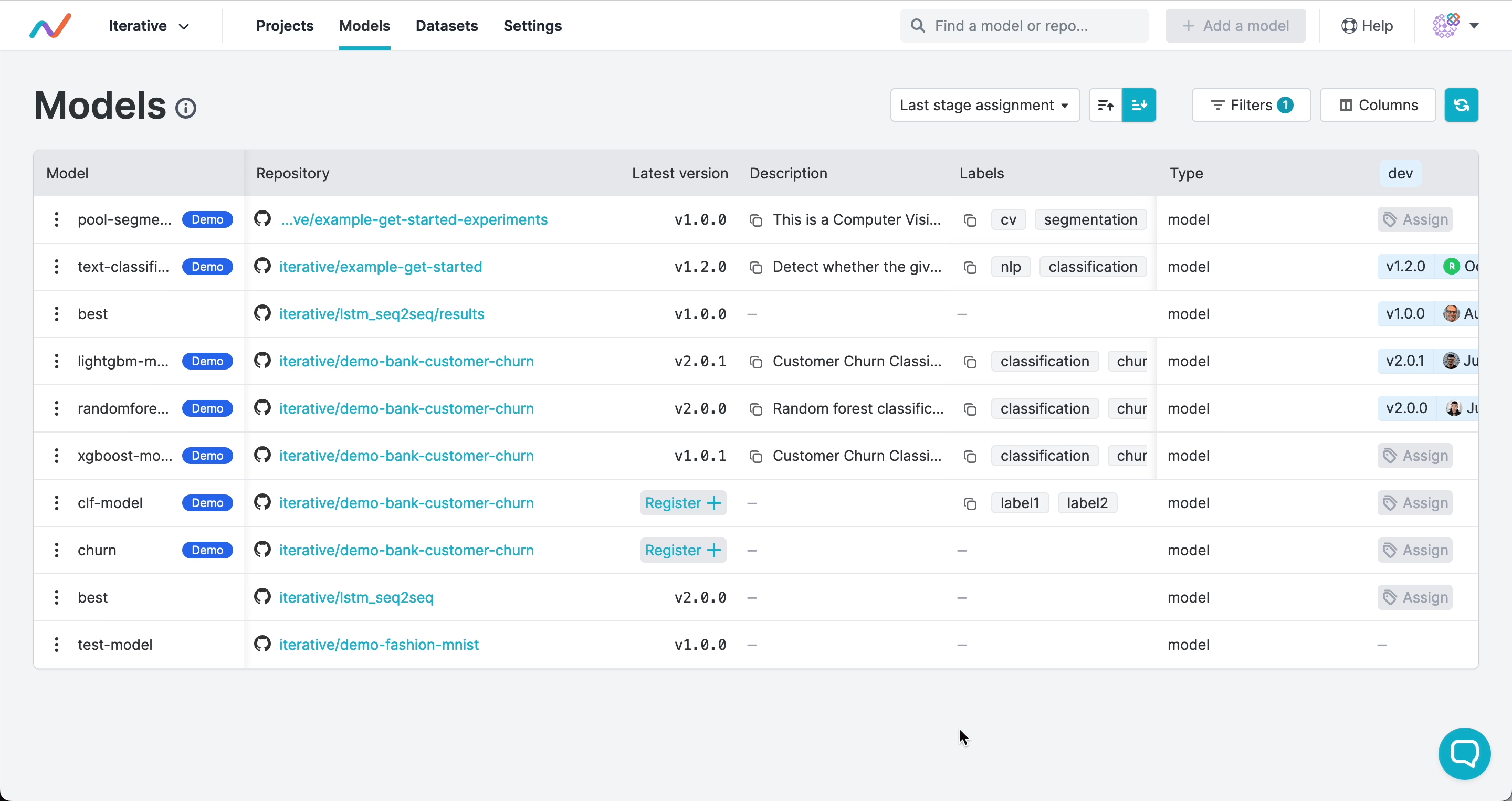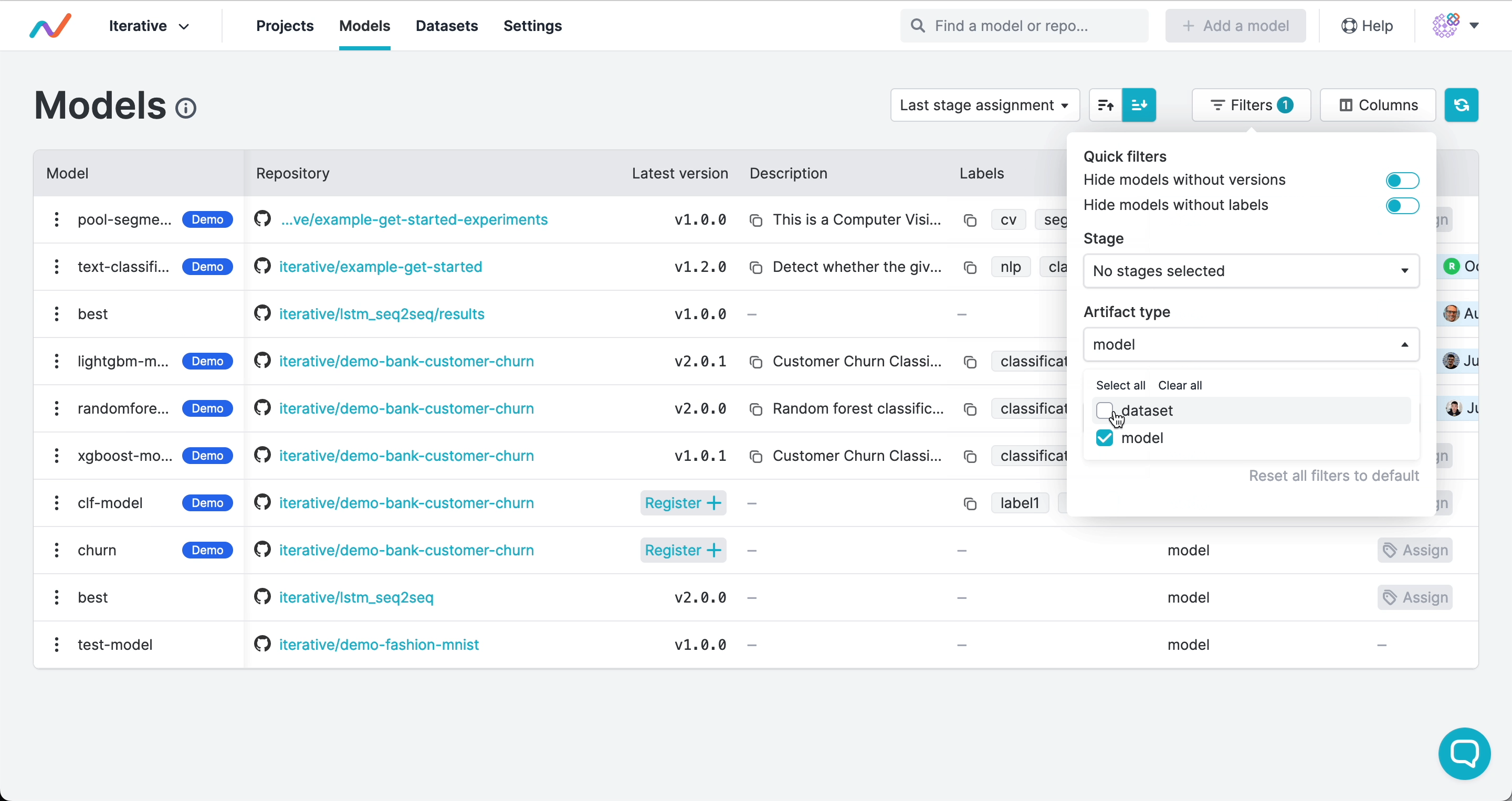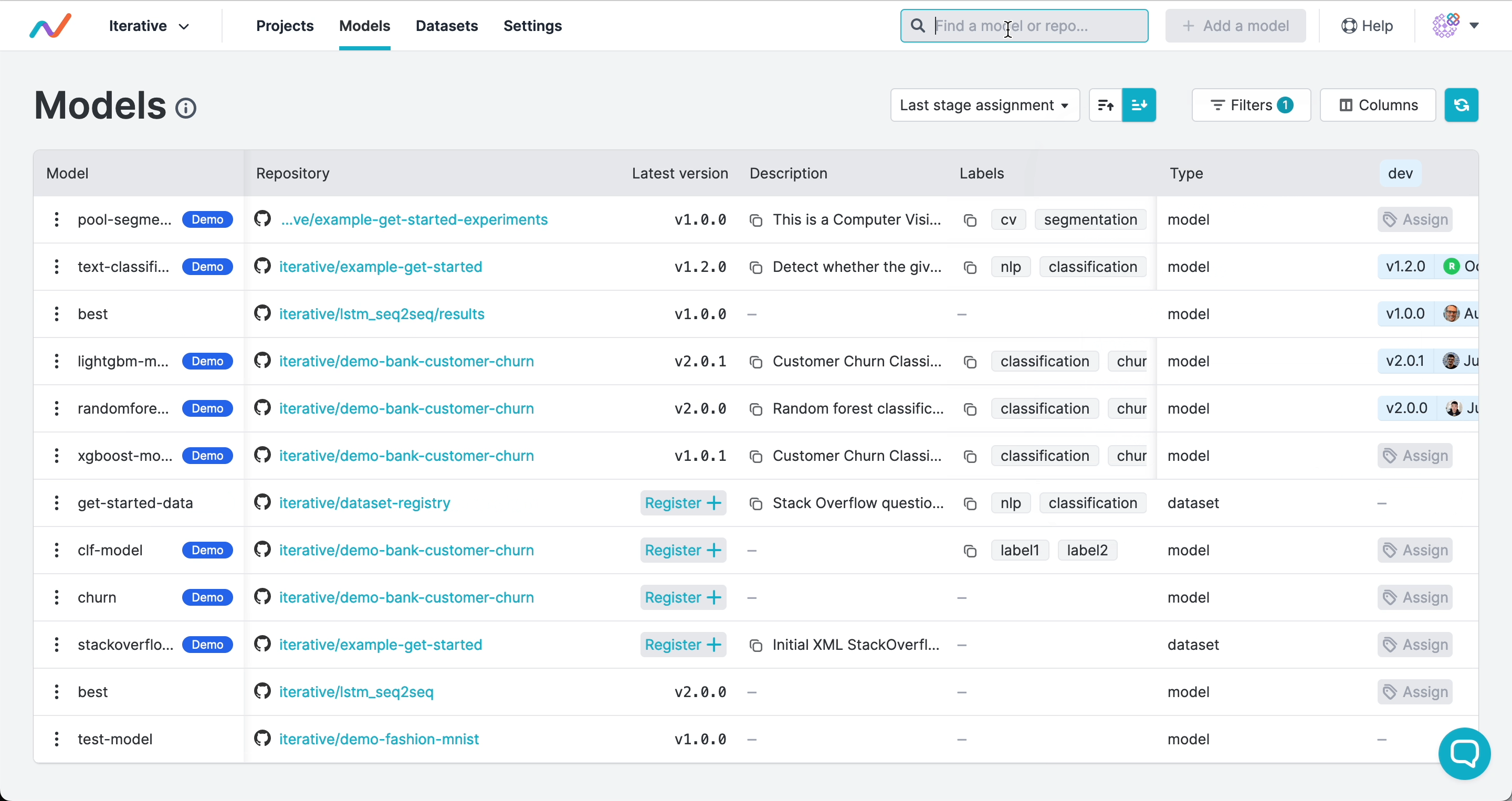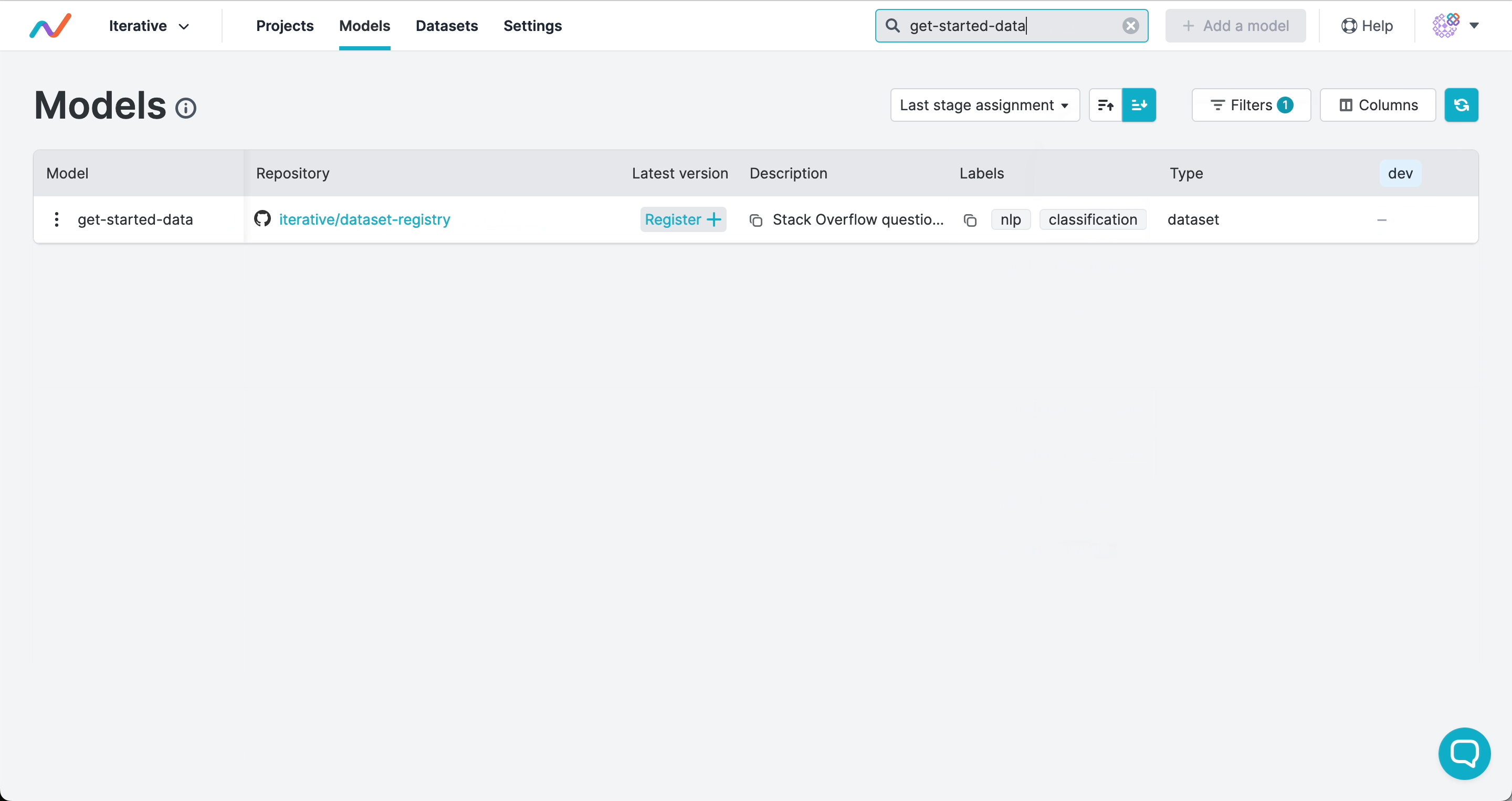
Now you know how to to build a lightweight data registry, update it, and get files from it. As your registry or team continues to grow, you may have trouble managing all artifacts across multiple projects. How do you keep them organized, or know which version to use, or share them with others outside your team? DVC along with DVC Studio can help you scale your registry and address these questions.
Adding metadata
You can record additional metadata about artifacts to help organize
them and make it easy for others to discover them. Add aliases and other
metadata to a dvc.yaml file in your project:
# dvc.yaml
artifacts:
get-started-data:
path: get-started/data.xml.dvc
type: data
desc: 'Stack Overflow questions'
labels:
- nlp
- classificationOnce you git commit and git push this info to a project that's connected to
DVC Studio, anyone on your team can see it and filter or search across all your
projects in the model registry. Although the artifact above is not a
model, you can change the filters to use it for any type of artifact:
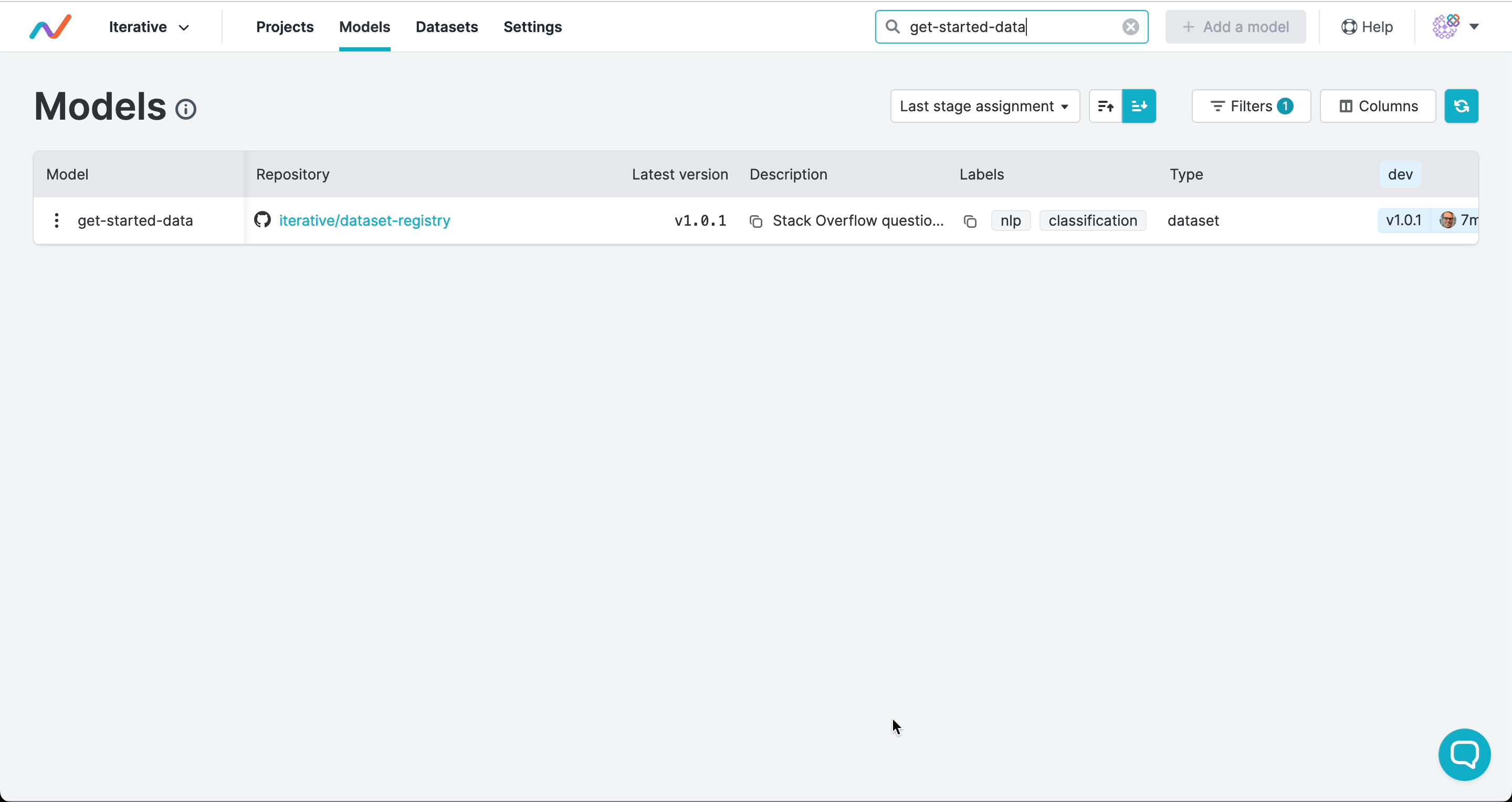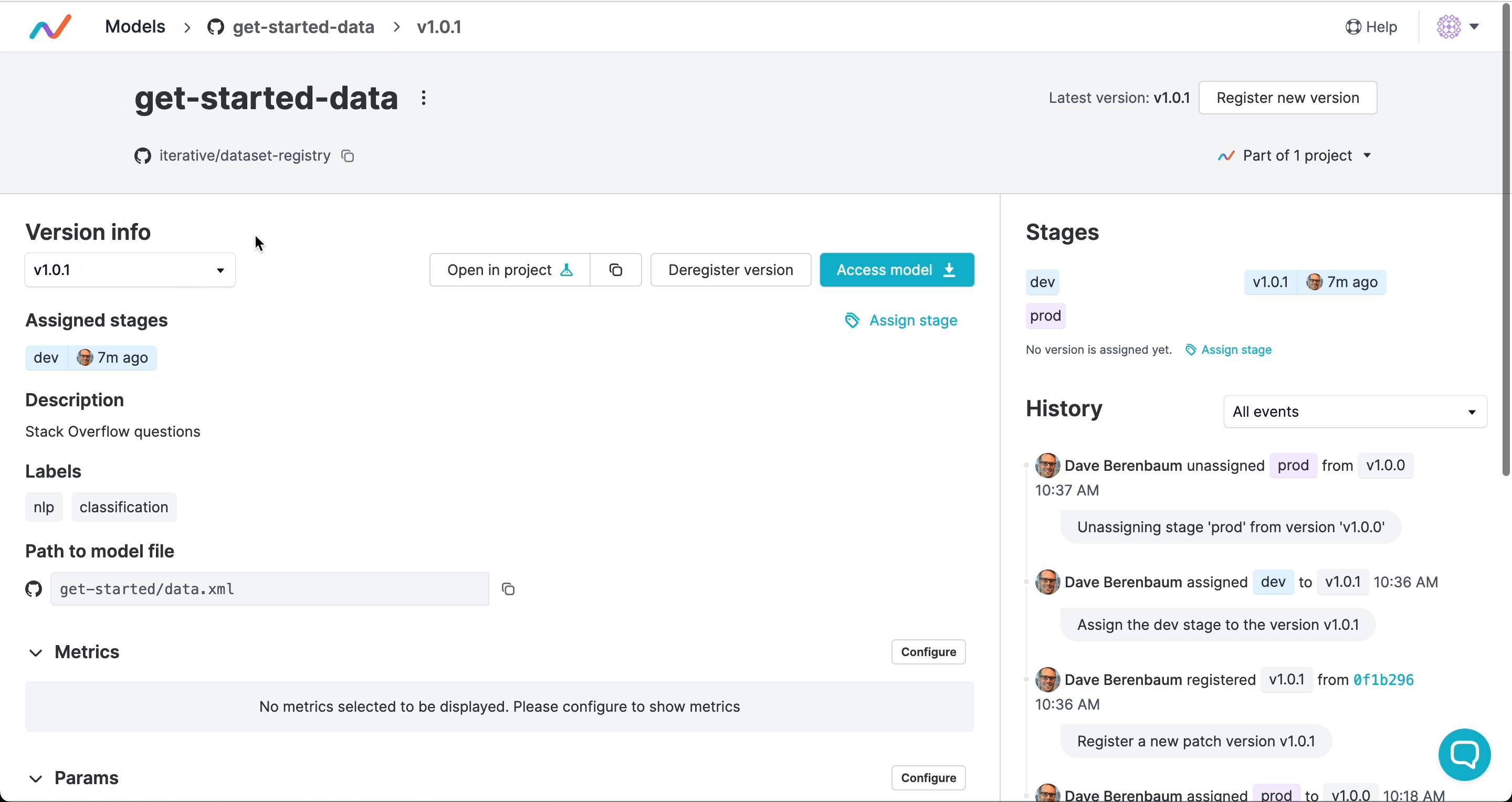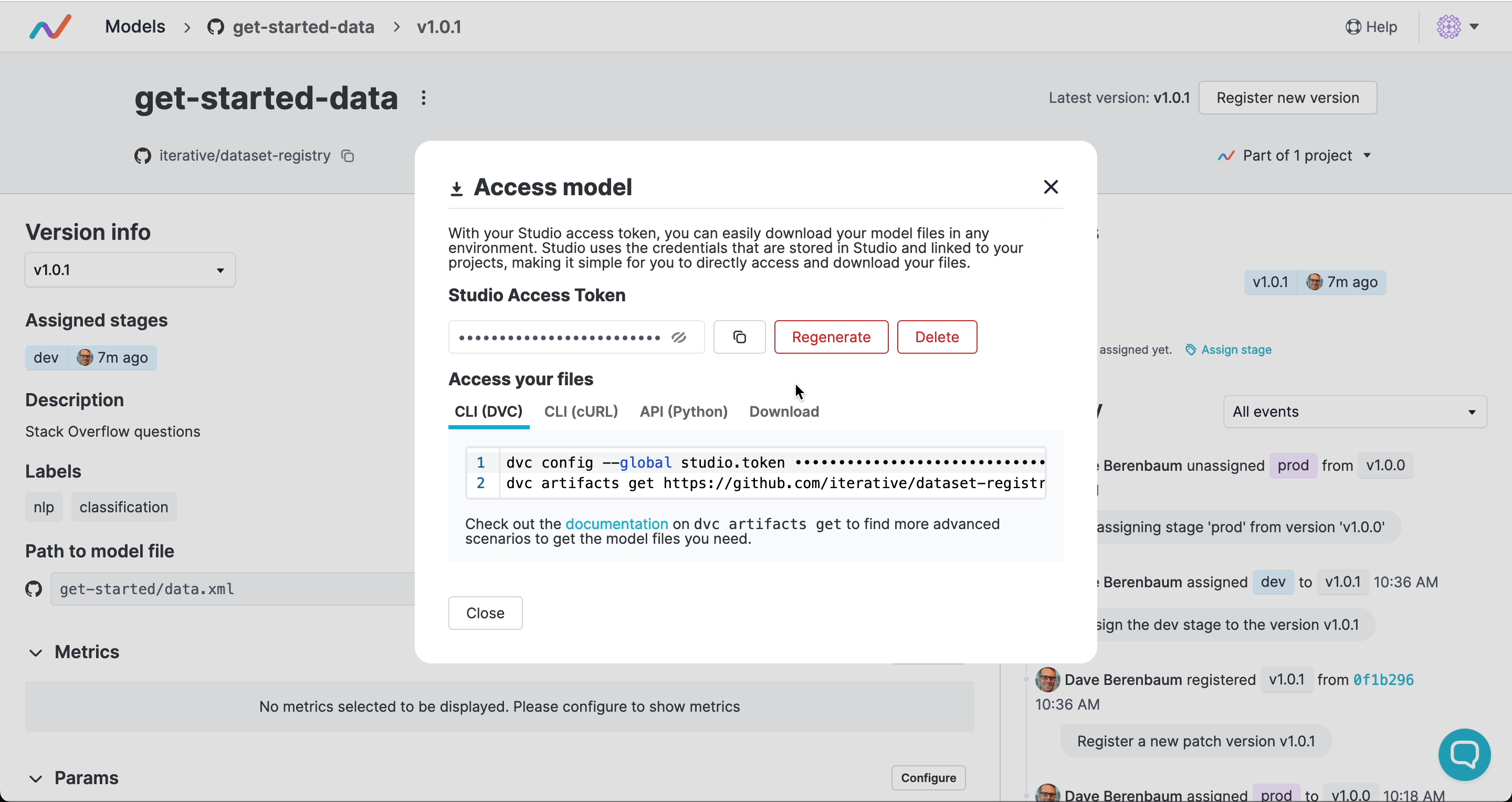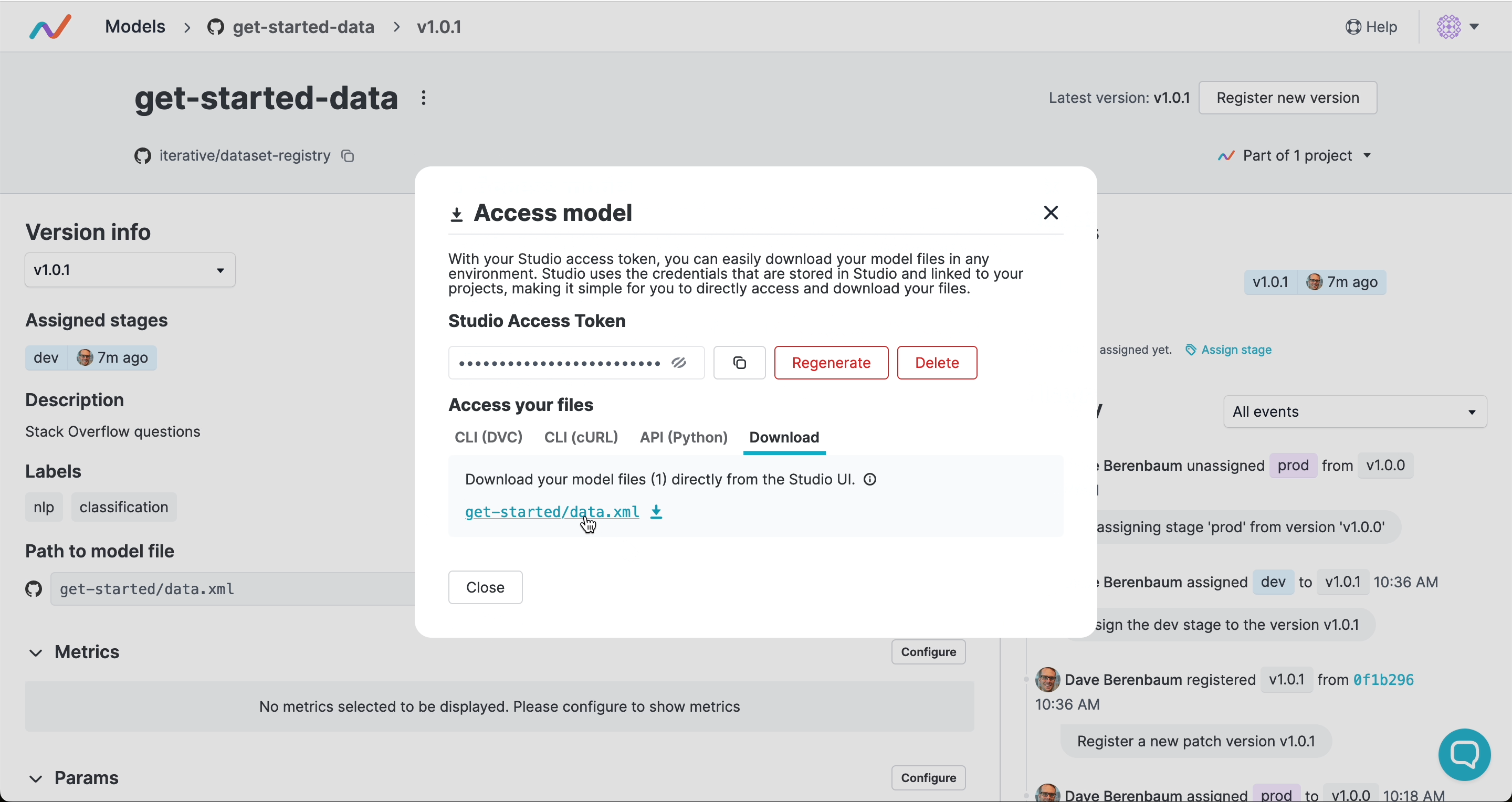
Registering versions and assigning stages
Version numbers and stages signal the commit to use and can trigger automated workflows. Just like with software, you can use semantic versioning to tag releases of your artifacts and to mark artifact versions as in production, development, or other stages of their lifecycle:
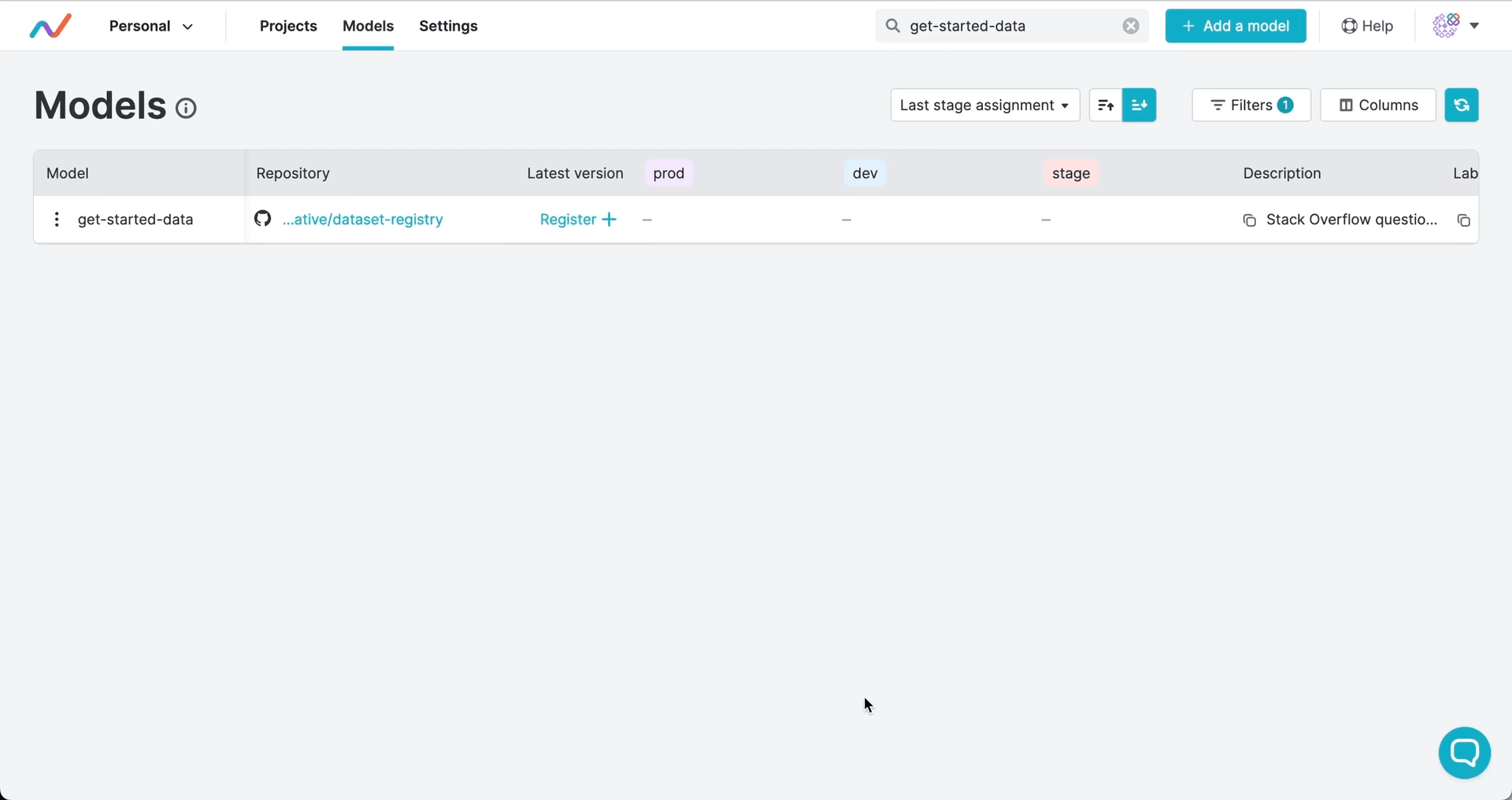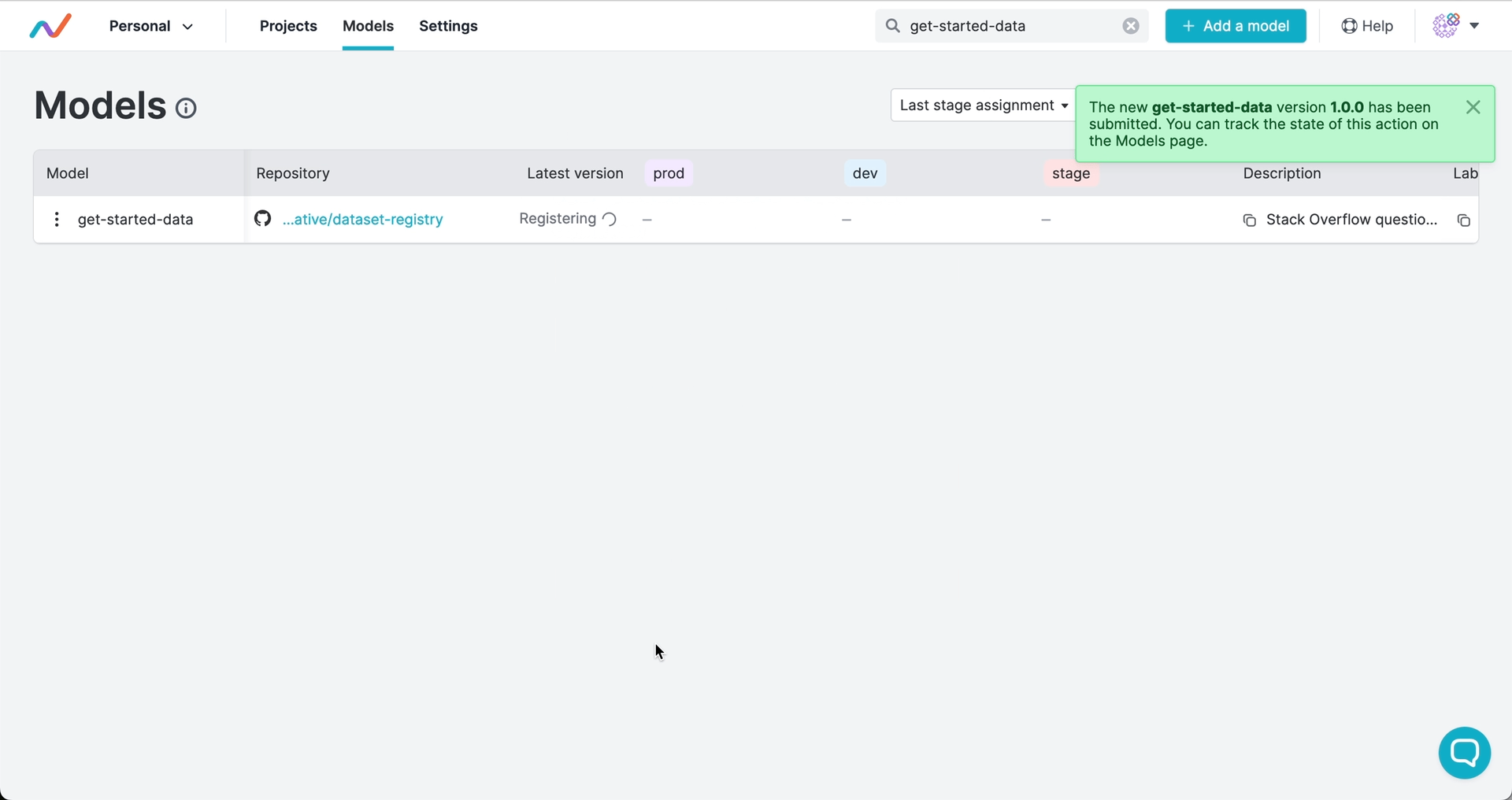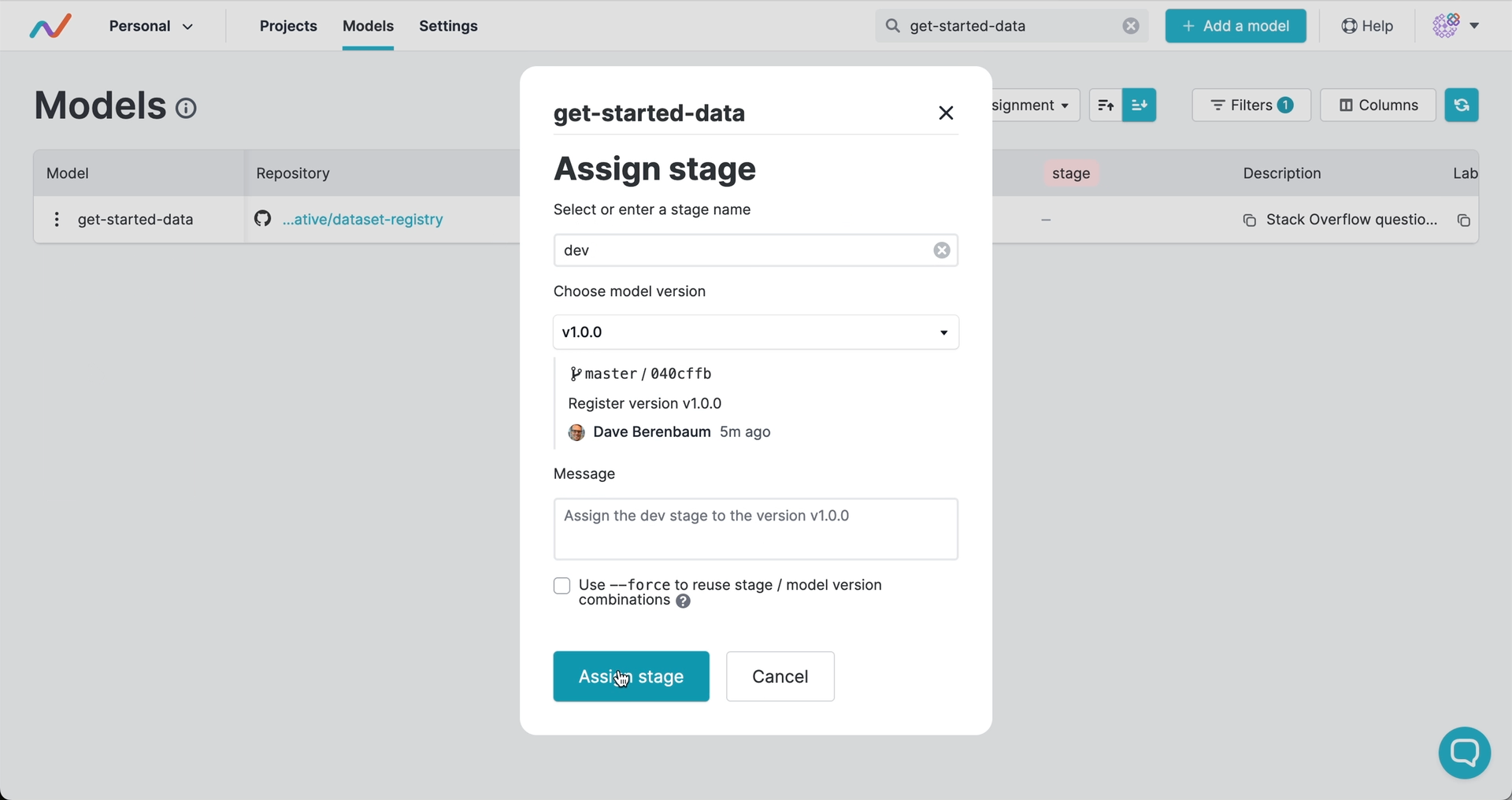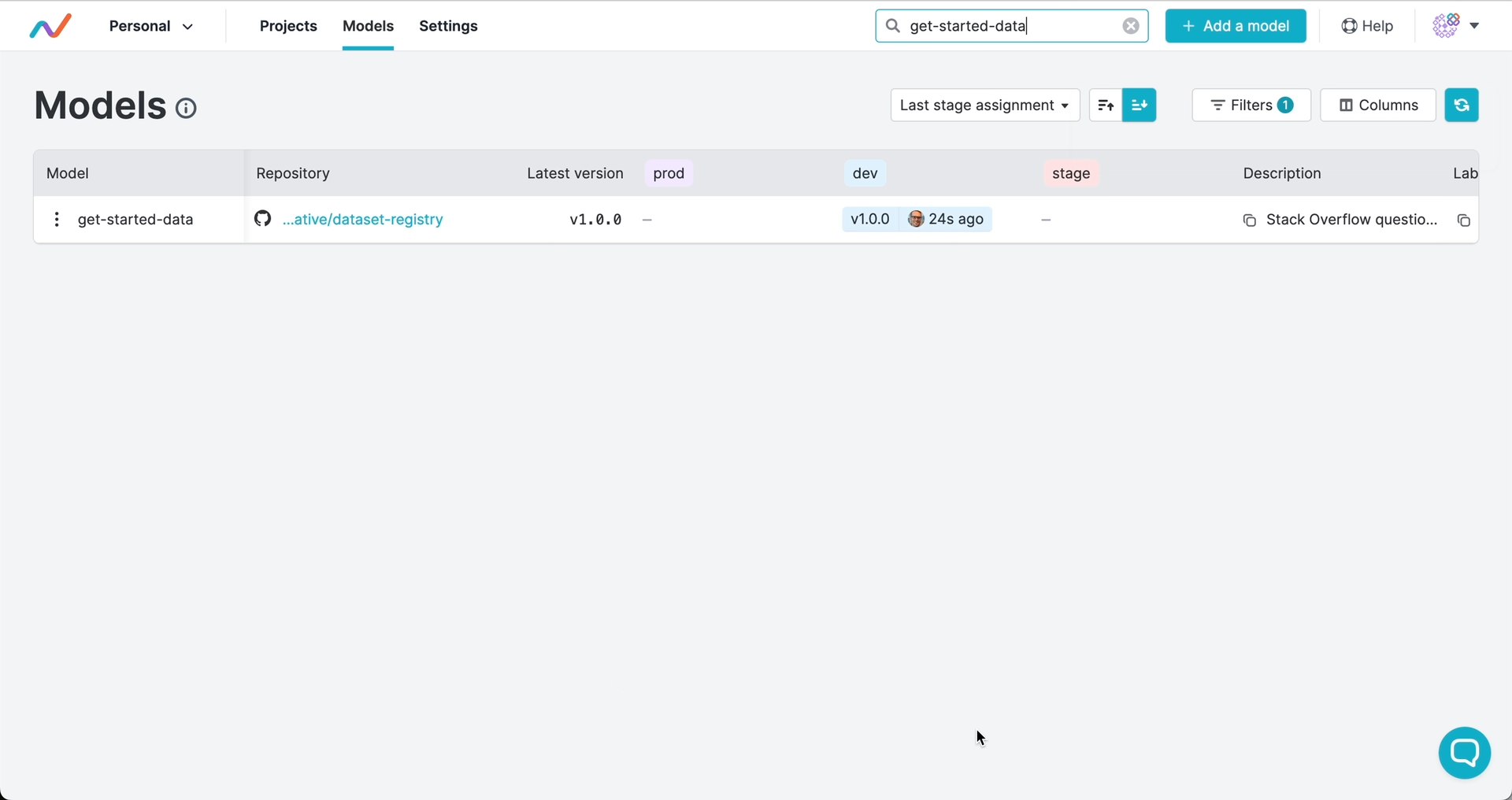
Versions and stages are saved as Git tags by GTO. This means that you have the full release history in Git, and you can trigger deployments, tests, or other actions in your CI/CD workflows when you register a version or assign a stage.
Accessing artifacts
Others can download or stream artifacts by their version or stage without needing access to your Git repository or cloud storage. If you connect your cloud credentials in DVC Studio, anyone on your team can access that artifact using only a Studio token, either in the UI or programmatically: